每天给你送来NLP技术干货!

作者:Gordon Lee (知乎)
paper:Don’t Miss the Labels: Label-semantic Augmented Meta-Learner for Few-Shot Text Classification
录取:ACL2021 Findings
重新编辑:zenRRan

这篇主要核心是挖掘class的语义,把class加到输入上面,去引导样本的特征表示。尤其是样本很少的情况下,样本很难学习到明确的class语义,容易对一些细粒度的类别(比如意图)产生混淆:比如两句话:北京有什么好玩的地方?告诉我去上海的旅行消息。其实这两个的细粒度意图是不一样的,前者是旅行建议,后者是旅行消息。但是没给class label的时候,模型可能会以为都表达的旅行目的地。
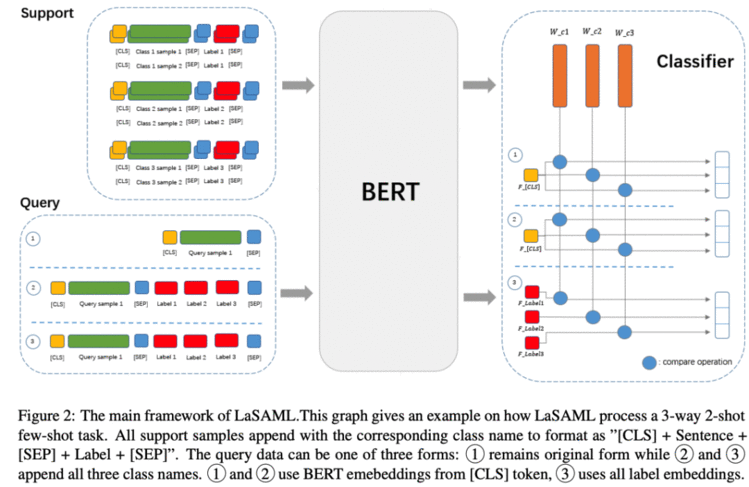
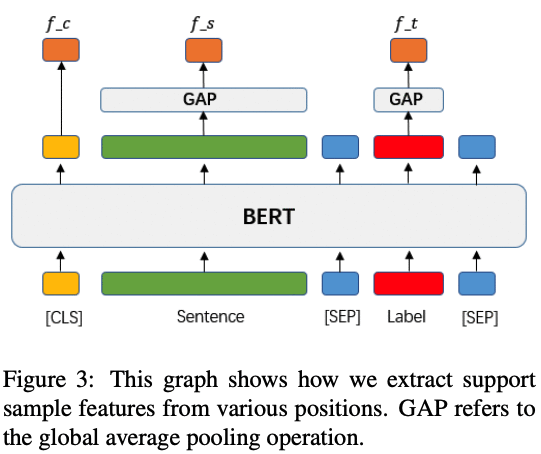
做法很简单,当然作者也探索了很多方式(如何提取支持集的样本特征,如何提取查询集的样本特征,用哪种网络,原型?匹配?关系?):一种好的实践,对于support set,将相应的class name加到输入,然后取cls位的特征,对于查询集,保持原样,不加任何的class name,取cls位的特征,然后用原型网络的做法。
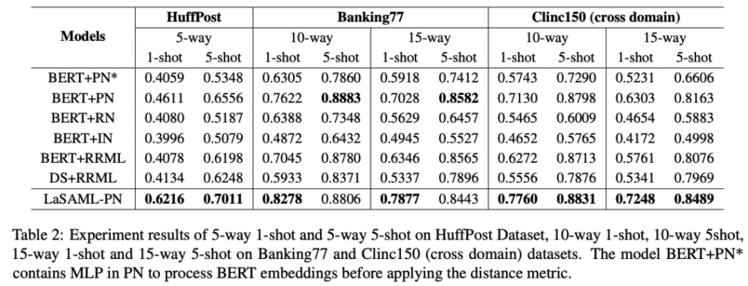
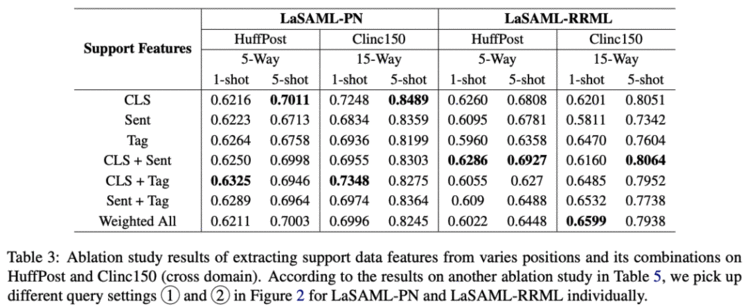
几个发现:样本越多,与类别相关的文本模式就越明显。但是,这可能取决于数据。一般来说,如果类之间的差异更细微,即细粒度的类,可能需要更多的样本,因此类名/定义的指导将更有益。最好不要引入随机化的参数,就像那个iclr那篇说的,适合这个类别的参数并不一定适合新类别,新领域的任务。怎么去提取样本的特征(要不要append,取哪个位置的特征)和数据集以及网络有关系,可以实验试试。

投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!







 京公网安备 11010802041100号
京公网安备 11010802041100号